> ## Documentation Index
> Fetch the complete documentation index at: https://wb-21fd5541-sdk-testing-latest.mintlify.site/llms.txt
> Use this file to discover all available pages before exploring further.
# ポイント集約
> W&Bの折れ線グラフにおける2つの点集約モード、フルフィデリティのバケット化サンプリングとランダムサンプリングについて説明します。
折れ線グラフでは、データ可視化の精度とパフォーマンスを向上させるために、点集約のmethodを使用できます。このページでは、使用可能な2つの集約モードと、それぞれの設定方法について説明します。これにより、Workspace に適した、詳細さとレンダリング速度の適切なトレードオフを選択できます。点集約モードには、[フルフィデリティ](#full-fidelity) と [ランダムサンプリング](#random-sampling) の2つのタイプがあります。W\&B ではデフォルトでフルフィデリティモードを使用します。
## フルフィデリティ
フルフィデリティはデフォルトの集約方法であり、データ内の極端な値を保持します。このセクションでは、フルフィデリティの仕組み、主な利点、単一のチャートまたは Workspace 全体でこれを有効にする方法について説明します。
フルフィデリティモードを使用すると、W\&B は X 軸 を動的なバケットに分割します。各線の点数は、グラフのサイズと run の数に応じて変化します。各バケット内の最小値と最大値 (オプションの陰影表示に使用) を計算し、主線の描画には各バケットの最後の値 (平均ではなく) を使用します。
ポイントの集約にフルフィデリティモードを使用する主な利点は 3 つあります。
* 極端な値やスパイクを保持できる: データ内の極端な値やスパイクを保持します。
* 最小値と最大値の表示方法を設定できる: W\&B App を使用して、極端な値 (最小値/最大値) を陰影付きの領域として表示するかどうかをインタラクティブに決定できます。
* データの忠実性を損なわずに探索できる: 特定のデータポイントにズームインすると、W\&B は X 軸 のバケットサイズを再計算します。これにより、精度を損なうことなくデータを探索しやすくなります。W\&B は以前に計算した集約結果をキャッシュして、読み込み時間の短縮に役立てます。これは、大規模なデータセット内を移動する場合に有用です。
### フルフィデリティを有効にする
W\&B ではデフォルトでフルフィデリティモードを使用します。手動で設定するには、次の step に従います:
1. Workspace にアクセスします。
2. 画面右上の **Add panels** ボタンの左にある歯車アイコンを選択します。
3. 表示される UI のスライダーから **折れ線グラフ** を選択します。
4. **ポイント集約** セクションで **Full fidelity** を選択します。
5. **Smoothing** のアルゴリズムと設定を指定します。
6. **Aggregation** を **Mean**、**Min**、または **Max** に設定します。
7. **Apply** をクリックします。
1. Workspace にアクセスします。
2. 左側のタブにある **Workspace** アイコンを選択します。
3. 設定するラインプロットパネルにカーソルを合わせ、歯車アイコンをクリックします。
4. 表示されるモーダルで、**Point aggregation method** を **Full fidelity** に設定します。
5. **Smoothing** のアルゴリズムと設定を指定します。
6. **Apply** をクリックします。
### 陰影表示を設定する
陰影表示では各 バケット 内のばらつきを可視化できるため、線の周囲に点がどの程度広がっているかを確認できます。フルフィデリティの折れ線グラフでは、陰影表示された領域に次を表示できます。
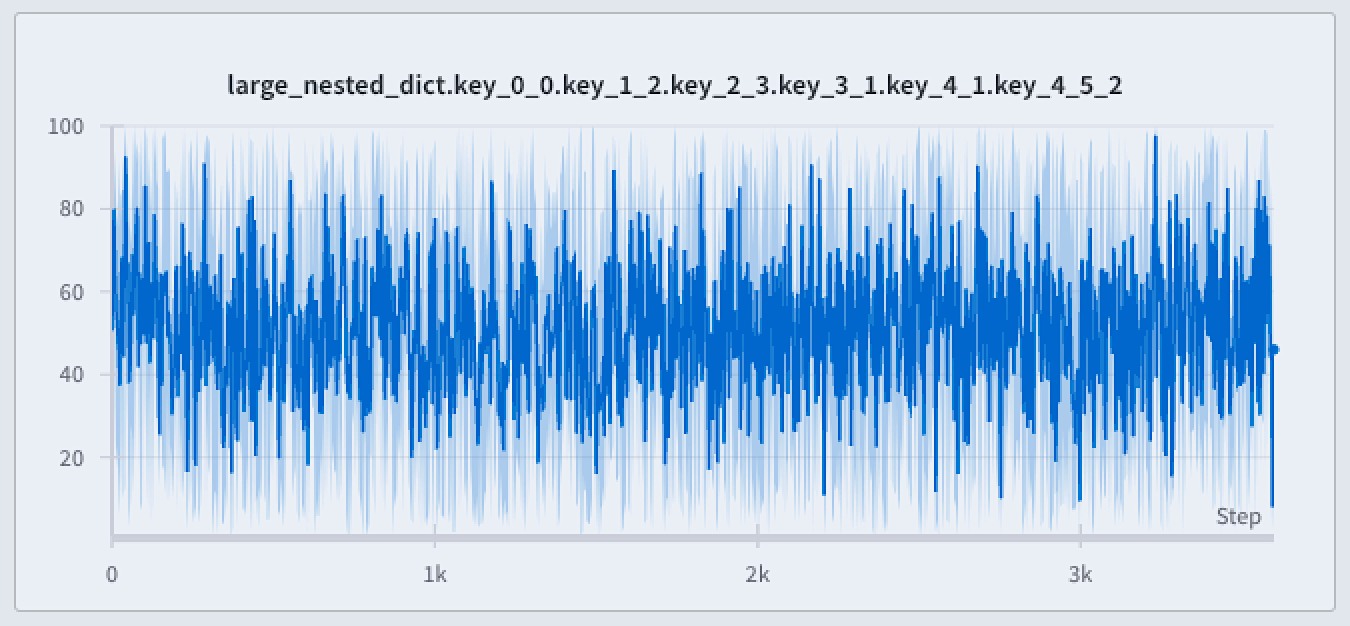
* **Min/Max**: 各 X 軸ポイントについて、最小値と最大値の間の領域を陰影表示します。陰影表示領域には、各 バケット における最小値から最大値までのすべての点が表示されます。
```math theme={null}
\text{Min/Max Range} = [\min(x_1, x_2, \ldots, x_n),\ \max(x_1, x_2, \ldots, x_n)]
```
ここで、$x_1, x_2, \ldots, x_n$ は特定の バケット 内の値です。
* **Standard deviation**: 各 X 軸ポイントについて、標準偏差を使って値のばらつきを計算し、その範囲を陰影表示します。
```math theme={null}
SD = \sqrt{\frac{1}{n}\sum_{i=1}^{n}(x_i - \overline{x})^2}
```
* **Standard error**: 各 X 軸ポイントについて、値をサンプルサイズの平方根で割って標準誤差を計算し、その範囲を陰影表示します。
```math theme={null}
SE = \frac{SD}{\sqrt{n}}
```
* **None**: 陰影表示なし (デフォルト) 。
次の画像は青い折れ線グラフを示しています。薄い青の陰影表示領域は、各 バケット の最小値と最大値を表しています。
 陰影表示を設定するには、次の手順を実行します。
1. Workspace にアクセスします。
2. 折れ線グラフにカーソルを合わせ、歯車アイコンをクリックします。
3. **Data** タブで、必要に応じて **ポイント集約** を **Full fidelity** に設定し、スムージングアルゴリズムを設定します。
4. **Grouping** タブで、**Group runs** をオンにします。必要に応じて、**Group by** を run の属性に設定します。
5. **Agg** を **Mean** (デフォルト) 、**Min**、または **Max** に設定します。
6. **Range** を **Min/Max**、**Std Dev**、**Std Err**、または **None** に設定します。
7. **Apply** をクリックします。
陰影表示を設定するには、次の手順を実行します。
1. Workspace にアクセスします。
2. 折れ線グラフにカーソルを合わせ、歯車アイコンをクリックします。
3. **Data** タブで、必要に応じて **ポイント集約** を **Full fidelity** に設定し、スムージングアルゴリズムを設定します。
4. **Grouping** タブで、**Group runs** をオンにします。必要に応じて、**Group by** を run の属性に設定します。
5. **Agg** を **Mean** (デフォルト) 、**Min**、または **Max** に設定します。
6. **Range** を **Min/Max**、**Std Dev**、**Std Err**、または **None** に設定します。
7. **Apply** をクリックします。
### データの忠実性を保ったままデータを探索する
極値やスパイクのような重要な点を見逃すことなく、データセットの特定の領域を分析できます。折れ線グラフをズームインすると、W\&B は各バケット内の最小値、最大値、最後の値を計算するためのバケットサイズを調整します。
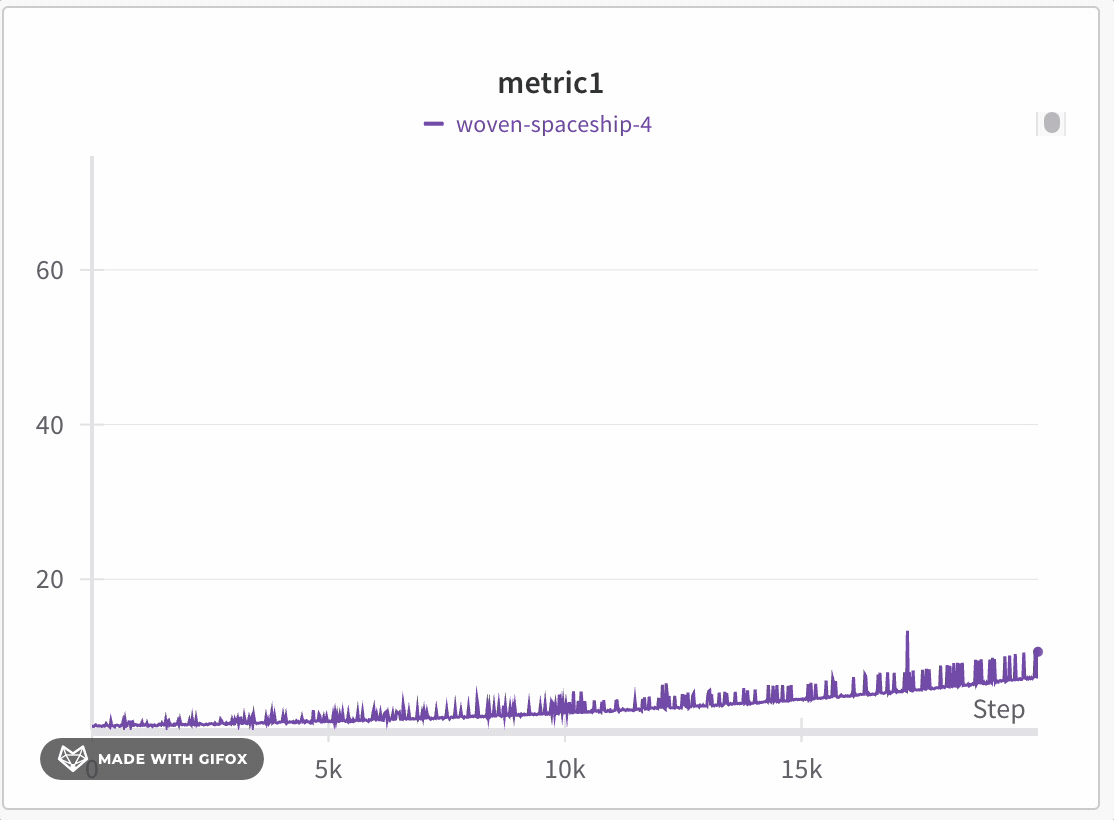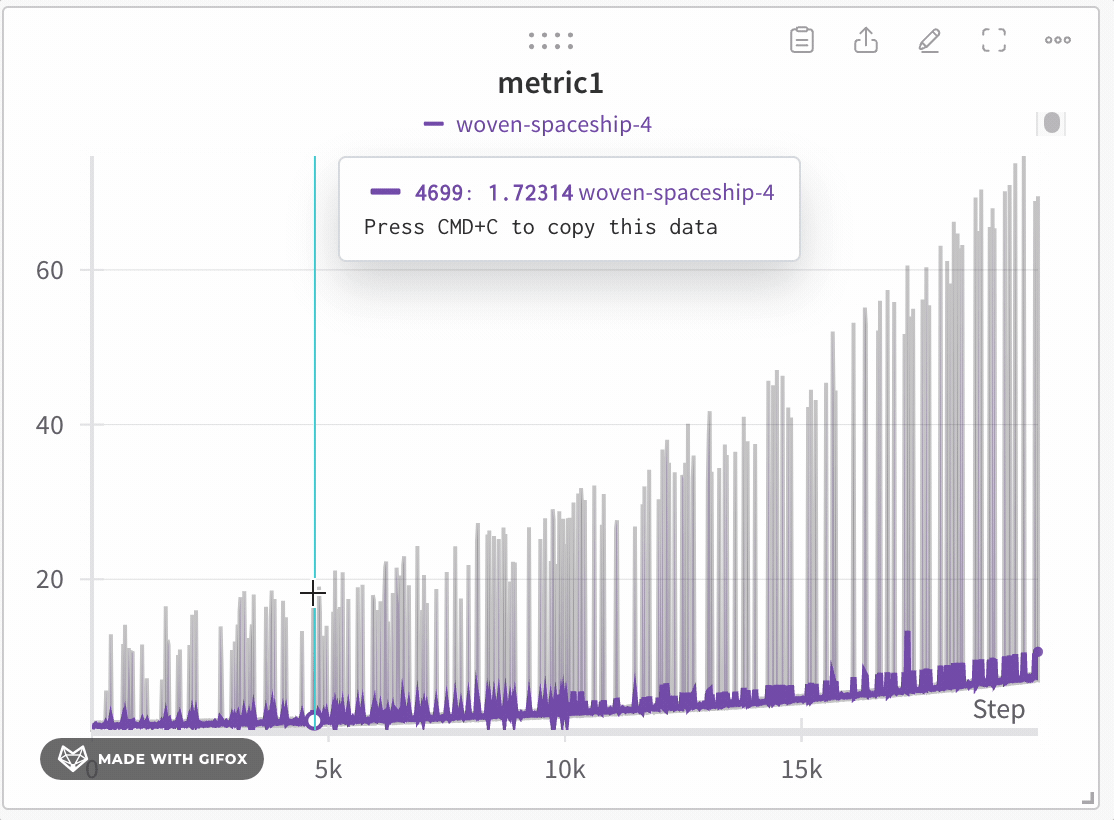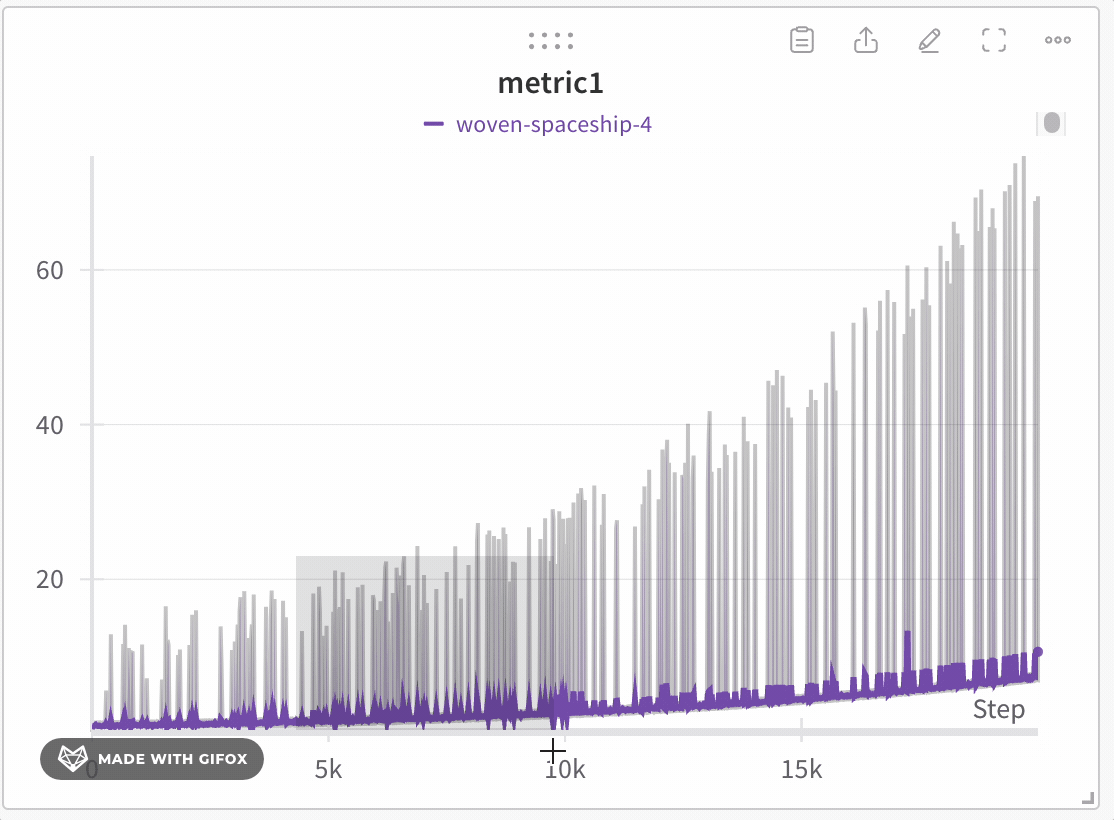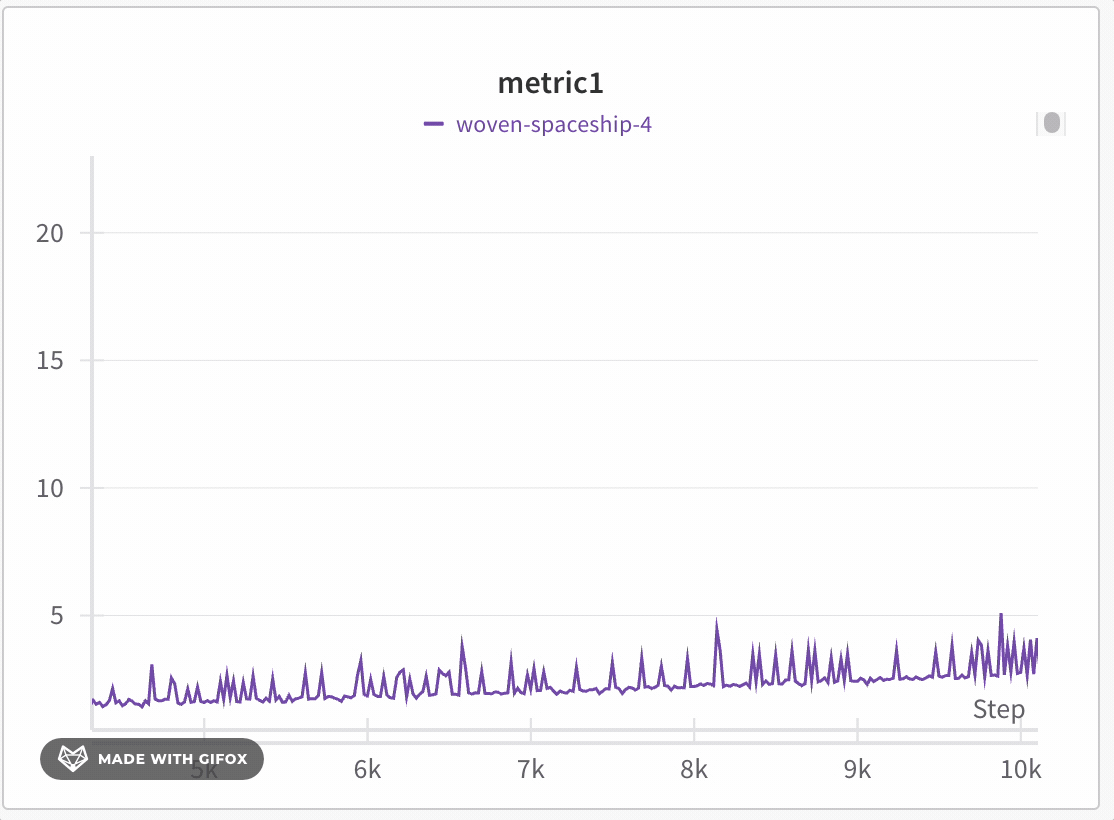 W\&B は動的ビニングを使用して x軸 をバケットに分割します。1 本の線あたりに表示される点の数は、グラフのサイズと run の数に応じて変化します。グラフのサイズが小さい場合や run が多い場合は、グラフの応答性を維持してより多くの線を表示できるよう、1 本の線あたりの点の数が少なくなることがあります。各バケットについて、W\&B は次の値を計算します。
* **最小値**: そのバケット内の最も低い値です (陰影表示に使用) 。
* **最大値**: そのバケット内の最も高い値です (陰影表示に使用) 。
* **線の値**: そのバケット内の最後の値で、線を描画するために使用されます。
W\&B は、データ全体の表現を保ちつつ、すべてのプロットに極値が含まれるように、バケット内の値をプロットします。線は各バケットの最後の値を結んで描画されます。十分にズームインすると、フルフィデリティモードでは追加の集約なしですべてのデータポイントを表示できます。正確なしきい値は、現在のグラフのサイズと run の数によって異なります。
折れ線グラフをズームインするには、次の step に従います:
1. W\&B のプロジェクトにアクセスする。
2. 左側のタブにある **Workspace** アイコンを選択します。
3. 必要に応じて Workspace にラインプロットパネルを追加するか、既存のラインプロットパネルにアクセスします。
4. クリックしてドラッグし、ズームインしたい特定の領域を選択します。
**Line Plot Grouping と式**
Line Plot Grouping を使用すると、W\&B は選択したモードに応じて次を適用します。
* **非ウィンドウ サンプリング (grouping) **: x軸 上で run 間の点を揃えます。複数の点が同じ x 値を共有する場合は平均が取られ、そうでない場合は個別の点として表示されます。
* **ウィンドウ サンプリング (grouping と式) **: x軸 を 250 個のバケット、または最も長い線の点数のいずれか小さい方に分割します。W\&B は各バケット内の点の平均を取ります。
* **フルフィデリティ (grouping と式) **: 非ウィンドウ サンプリングと似ていますが、パフォーマンスと詳細度のバランスを取るため、run ごとに最大 500 点まで取得します。
W\&B は動的ビニングを使用して x軸 をバケットに分割します。1 本の線あたりに表示される点の数は、グラフのサイズと run の数に応じて変化します。グラフのサイズが小さい場合や run が多い場合は、グラフの応答性を維持してより多くの線を表示できるよう、1 本の線あたりの点の数が少なくなることがあります。各バケットについて、W\&B は次の値を計算します。
* **最小値**: そのバケット内の最も低い値です (陰影表示に使用) 。
* **最大値**: そのバケット内の最も高い値です (陰影表示に使用) 。
* **線の値**: そのバケット内の最後の値で、線を描画するために使用されます。
W\&B は、データ全体の表現を保ちつつ、すべてのプロットに極値が含まれるように、バケット内の値をプロットします。線は各バケットの最後の値を結んで描画されます。十分にズームインすると、フルフィデリティモードでは追加の集約なしですべてのデータポイントを表示できます。正確なしきい値は、現在のグラフのサイズと run の数によって異なります。
折れ線グラフをズームインするには、次の step に従います:
1. W\&B のプロジェクトにアクセスする。
2. 左側のタブにある **Workspace** アイコンを選択します。
3. 必要に応じて Workspace にラインプロットパネルを追加するか、既存のラインプロットパネルにアクセスします。
4. クリックしてドラッグし、ズームインしたい特定の領域を選択します。
**Line Plot Grouping と式**
Line Plot Grouping を使用すると、W\&B は選択したモードに応じて次を適用します。
* **非ウィンドウ サンプリング (grouping) **: x軸 上で run 間の点を揃えます。複数の点が同じ x 値を共有する場合は平均が取られ、そうでない場合は個別の点として表示されます。
* **ウィンドウ サンプリング (grouping と式) **: x軸 を 250 個のバケット、または最も長い線の点数のいずれか小さい方に分割します。W\&B は各バケット内の点の平均を取ります。
* **フルフィデリティ (grouping と式) **: 非ウィンドウ サンプリングと似ていますが、パフォーマンスと詳細度のバランスを取るため、run ごとに最大 500 点まで取得します。
## ランダムサンプリング
ランダムサンプリングは、データの忠実性よりも描画速度を優先する代替の集約方法です。チャートのパフォーマンスを向上させたい場合で、すべての極端な値を保持する必要がない場合に使用してください。
ランダムサンプリングでは、ランダムに抽出した 1,500 個の点を使用して折れ線グラフを描画します。サンプリングによって点が間引かれるため、外れ値やスパイクを見つけにくくなります。
ランダムサンプリングは非決定的に行われます。そのため、データ内の外れ値やスパイクが除外される場合があり、データの精度が低下することがあります。
### ランダムサンプリングを有効にする
デフォルトでは、W\&B はフルフィデリティモードを使用します。ランダムサンプリングを有効にするには、次の step に従います。
1. W\&B のプロジェクトにアクセスする。
2. 左側のタブで **Workspace** アイコンを選択します。
3. 画面右上で、**Add panels** ボタンの左隣にある歯車アイコンを選択します。
4. 表示される UI スライダーで **折れ線グラフ** を選択します。
5. **ポイント集約** セクションで **ランダムサンプリング** を選択します。
1. W\&B のプロジェクトにアクセスする。
2. 左側のタブで **Workspace** アイコンを選択します。
3. ランダムサンプリングを有効にするラインプロットパネルを選択します。
4. 表示されるモーダル内の **Point aggregation method** セクションで **ランダムサンプリング** を選択します。
### サンプリングされていないデータにアクセスする
ランダムサンプリングによって必要なポイントが除外された場合でも、サンプリングされていない完全なメトリクス履歴には引き続きプログラムからアクセスできます。[W\&B Run API](/ja/models/ref/python/public-api/runs) を使用すると、run 中にログされたメトリクスの完全な履歴にアクセスできます。次の例では、特定の run の損失値を取得して処理する方法を示します。
```python theme={null}
# W&B API を初期化する
run = api.run("l2k2/examples-numpy-boston/i0wt6xua")
# 'Loss' メトリクスの履歴を取得する
history = run.scan_history(keys=["Loss"])
# 履歴から損失値を抽出する
losses = [row["Loss"] for row in history]
```